I discovered “An Introduction to Statistical Learning” (ISLR) a few years ago, and since then, it’s become my go-to reference for machine learning. Lately, I’ve been itching to dive deeper into the new edition—especially with the updated chapters, Python labs, and all the fresh content.
Between the book itself, the video lectures available on edX (and other platforms), and the awesome book club run by the DSLC community, I’ve really immersed myself in this world.
It’s been the perfect opportunity to revisit the fundamentals with a fresh, more relaxed mindset. Learning just for the joy of it—rather than to pass a test—is a totally different experience. And honestly, it’s so much more satisfying.
To keep a record of this deep dive, I decided to start a blog. The good news? It’s incredibly easy to set up with Quarto, and hosting it on GitHub is a breeze.
I’m not trying to summarize the book or highlight the key concepts. That’s not the goal. I just want to take the time to explore the parts that speak to me—to reflect, to play, to understand better. Kind of like a personal study journal, but online.
1-Classification
Bayses classifiers
Let us focus on understanding the differences between 3 classifiers : Naive Bayses, Linear Discriminant Analysis, and Quadratic Discriminant Analysis.
Naive Bayses assume that within the kth class, the p preditors are independent.
LDA assume that the observations are drawn from a multivariate Gaussian \(X \sim \mathcal{N}(\mu_k, \Sigma)\)
QDA assume that each class has its own covariance matrix \(X \sim \mathcal{N}(\mu_k, \Sigma_k)\)
Principle: We model the distribution of X in each of the classes separately and then we use Bayses theorem to flip things around to obtain Pr(Y|X). By choice, we use the normal (Gaussian) distribution.
\[
Pr(Y = k \mid X = x) = \frac{\pi_k f_k(x) }{\sum_{l=1}^{K} \pi_l*f_l(x)}
\]
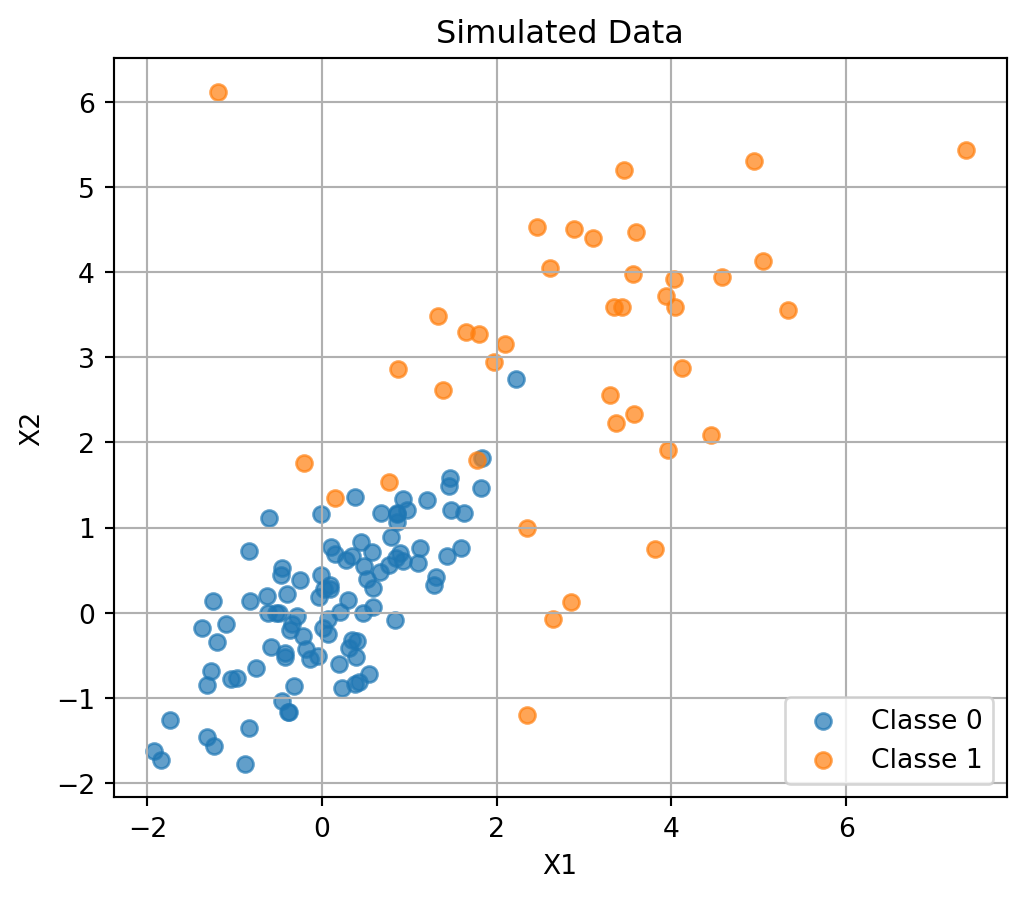
Let us just try on simulated data.
Comparation between “manual” and “sklearn” models
💻 Data Simulation
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.metrics import classification_report# Fixer le seed pour la reproductibiliténp.random.seed(42)# 2. Taille des classesn_0 =100# classe majoritairen_1 =40# classe minoritaire# 3. Paramètres des distributions# Classe 0 : petite variance, forte corrélationmean_0 = [0, 0]cov_0 = [[1, 0.8], [0.8, 1]]X0 = np.random.multivariate_normal(mean_0, cov_0, size=n_0)y0 = np.zeros(n_0)# Classe 1 : plus grande variance, faible corrélationmean_1 = [3, 3]cov_1 = [[2, 0.2], [0.2, 2]]X1 = np.random.multivariate_normal(mean_1, cov_1, size=n_1)y1 = np.ones(n_1)# 4. Fusionner les donnéesX = np.vstack((X0, X1))y = np.hstack((y0, y1))# Mise en DataFrame# 5. Création du DataFramedf = pd.DataFrame(X, columns=["X1", "X2"])df["Y"] = y.astype(int)from sklearn.preprocessing import StandardScalerscaler = StandardScaler(with_mean=True, with_std=True, copy=True)scaler.fit(df[['X1', 'X2']])X_std = scaler.transform(df[['X1', 'X2']]) df_scale = pd.DataFrame( X_std, columns=['X1', 'X2'])df_scale["Y"] = y.astype(int)
data(iris)
library(MASS)
iris.d <- iris[,1:4] # the data
iris.c <- iris[,5] # the classes
sc_obj <- stepclass(iris.d, iris.c, "lda", start.vars = "Sepal.Width")
sc_obj
plot(sc_obj)
## or using formulas:
sc_obj <- stepclass(Species ~ ., data = iris, method = "qda",
start.vars = "Sepal.Width", criterion = "AS") # same as above
sc_obj
## now you can say stuff like
## qda(sc_obj$formula, data = B3)